Benchmarks#
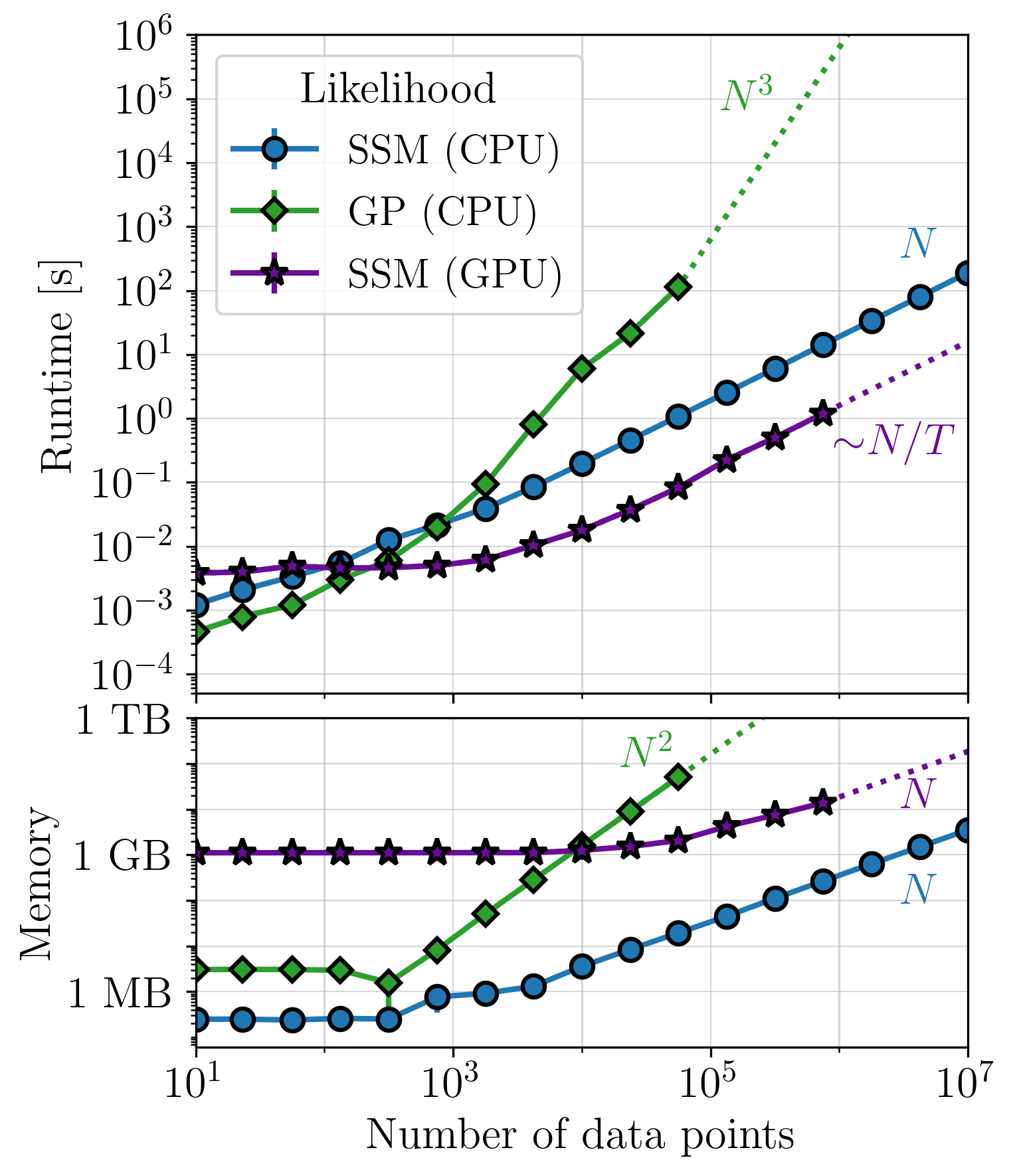
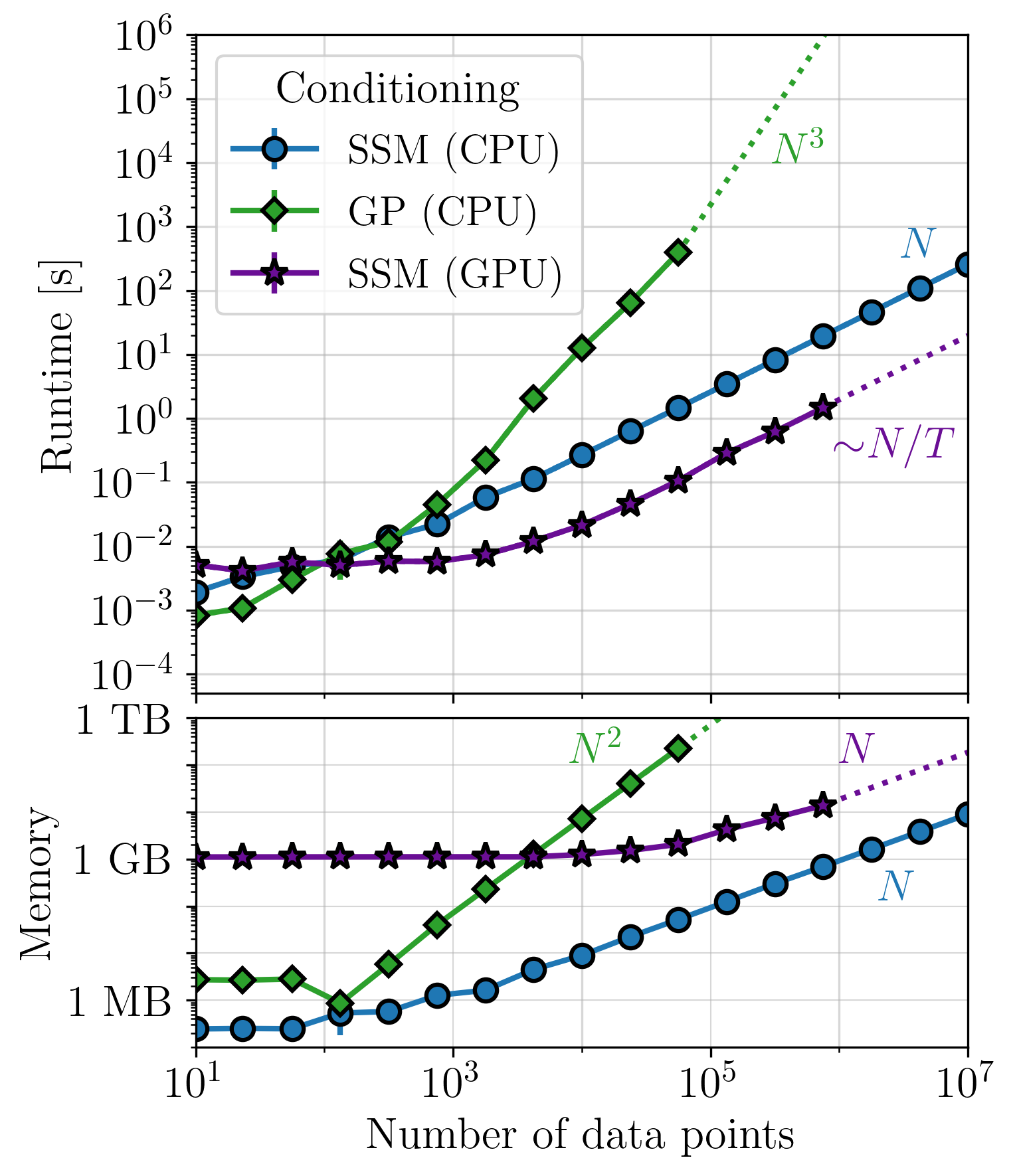
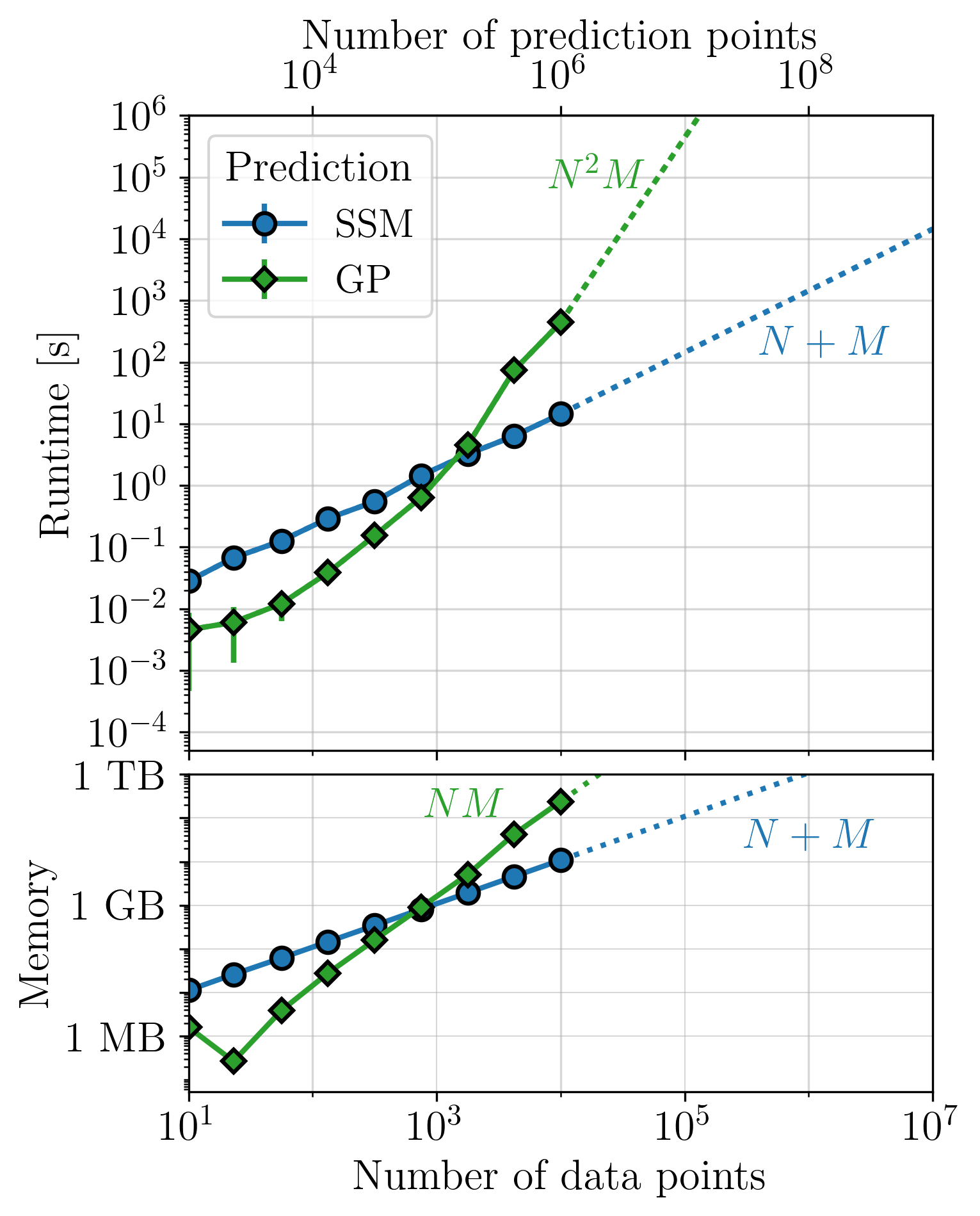
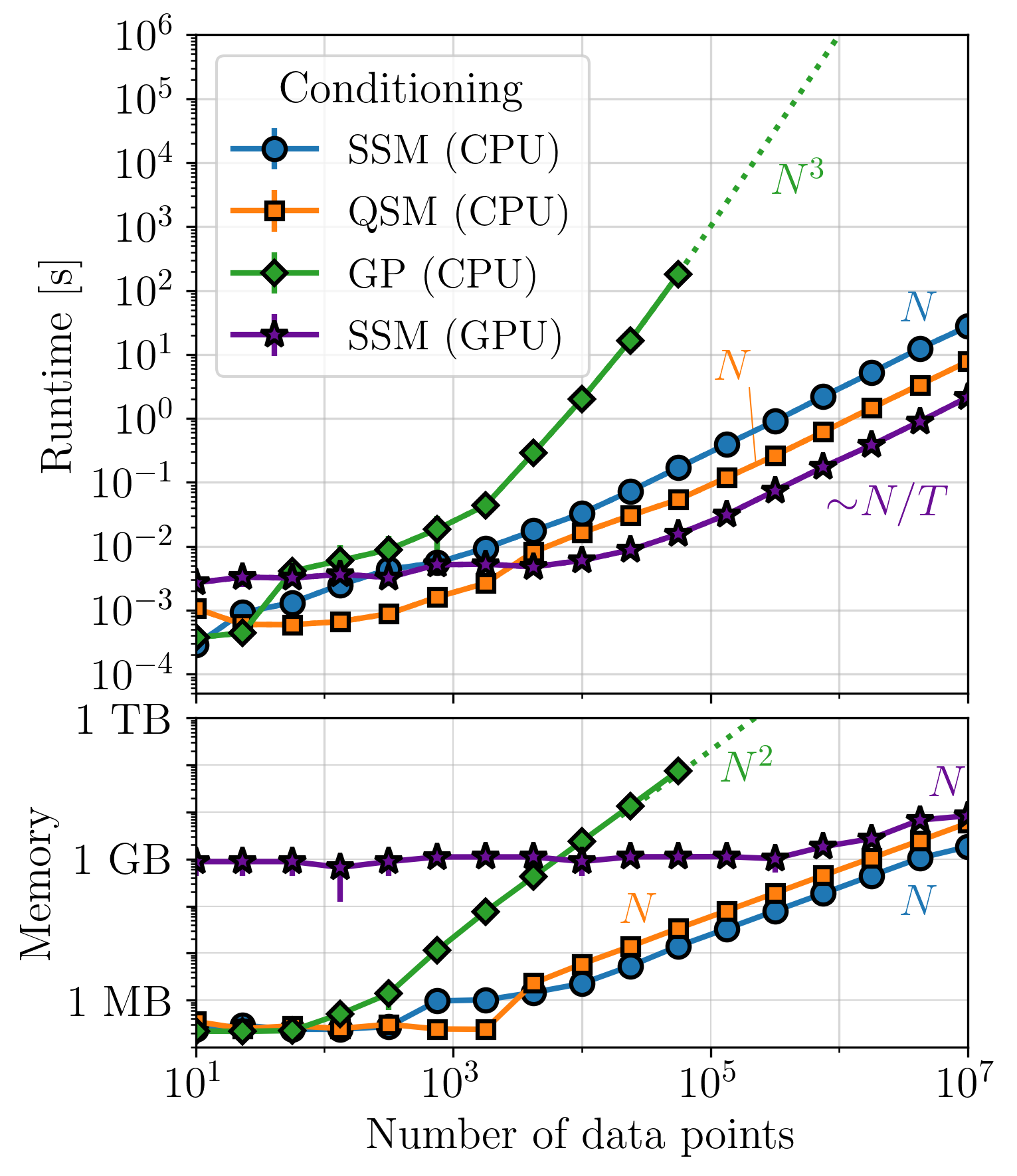
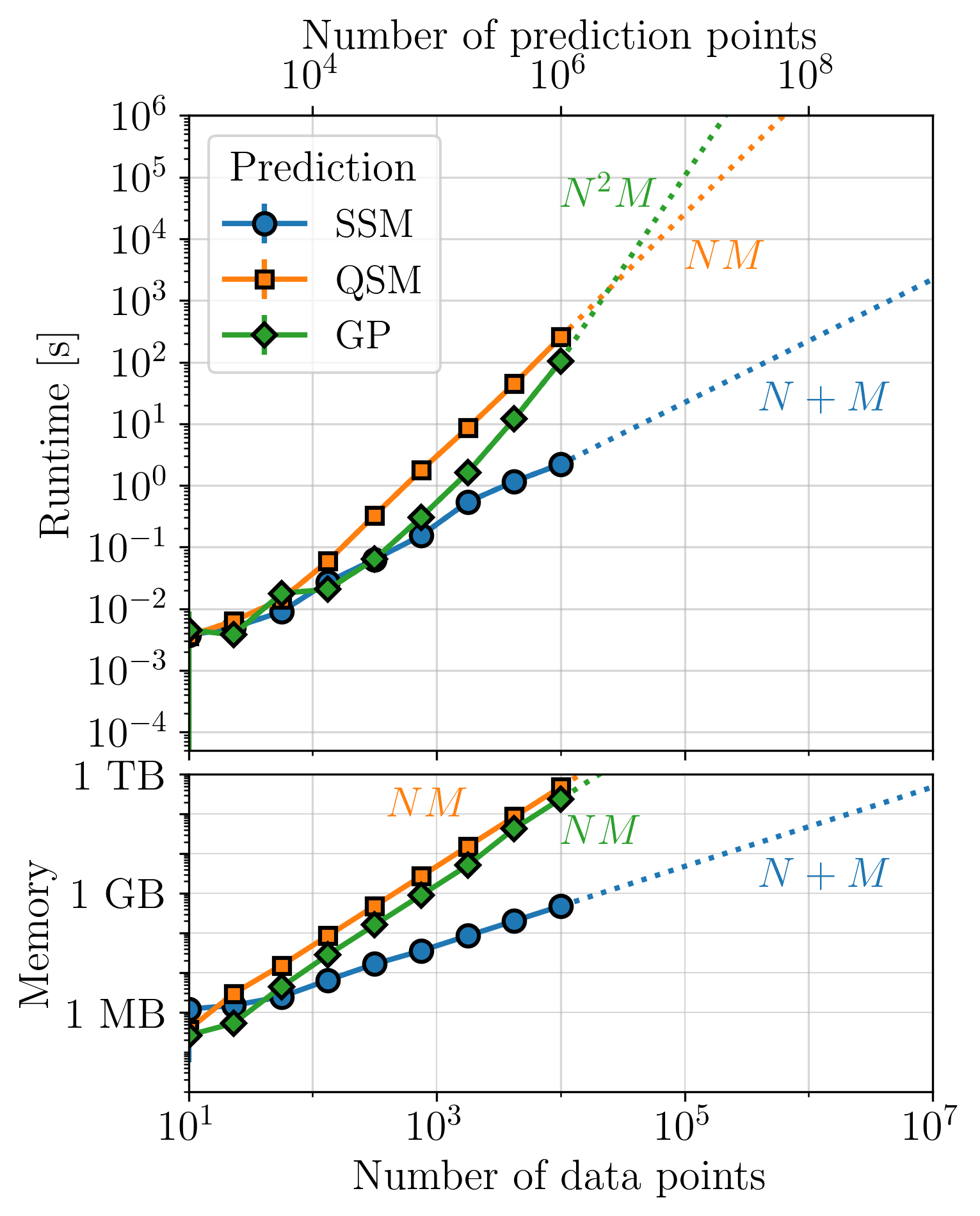
This page summarizes the key plots from Section 4 in Rubenzahl et al. 2026, which benchmark the performance of smolgp on CPU (blue curves) and GPU (purple curve) as compared to the same computations implemented in tinygp (green curve). Each set of plots benchmark the runtime and memory usage for computing the likelihood, conditioned mean and variance at the data points, and predicted mean and variance on a grid of points 100x as dense as the data.
Note
CPU benchmarks were run on an Intel® Xeon® w53435X with 512 GB RAM.
GPU benchmarks were run on an NVIDIA RTX 6000 Ada with 48 GB of GPU memory, running CUDA v12.8. The functions used for timing and memory profiling are located in tests/benchmark.
Instantaneous measurements#
For instantaneous measurements, and certain kernels[1], optimized quasiseparable matrix (QSM, orange curves) algebra can be leveraged with tinygp to achieve similar-to-better performance as the state space method. However, kernels which do not have quasiseparable representations but can be approximated by a state space model, such as the quasiperiodic kernel, will see significantly faster performance in smolgp. In all cases, predictions with large datasets are substantially faster and less memory intensive with smolgp.
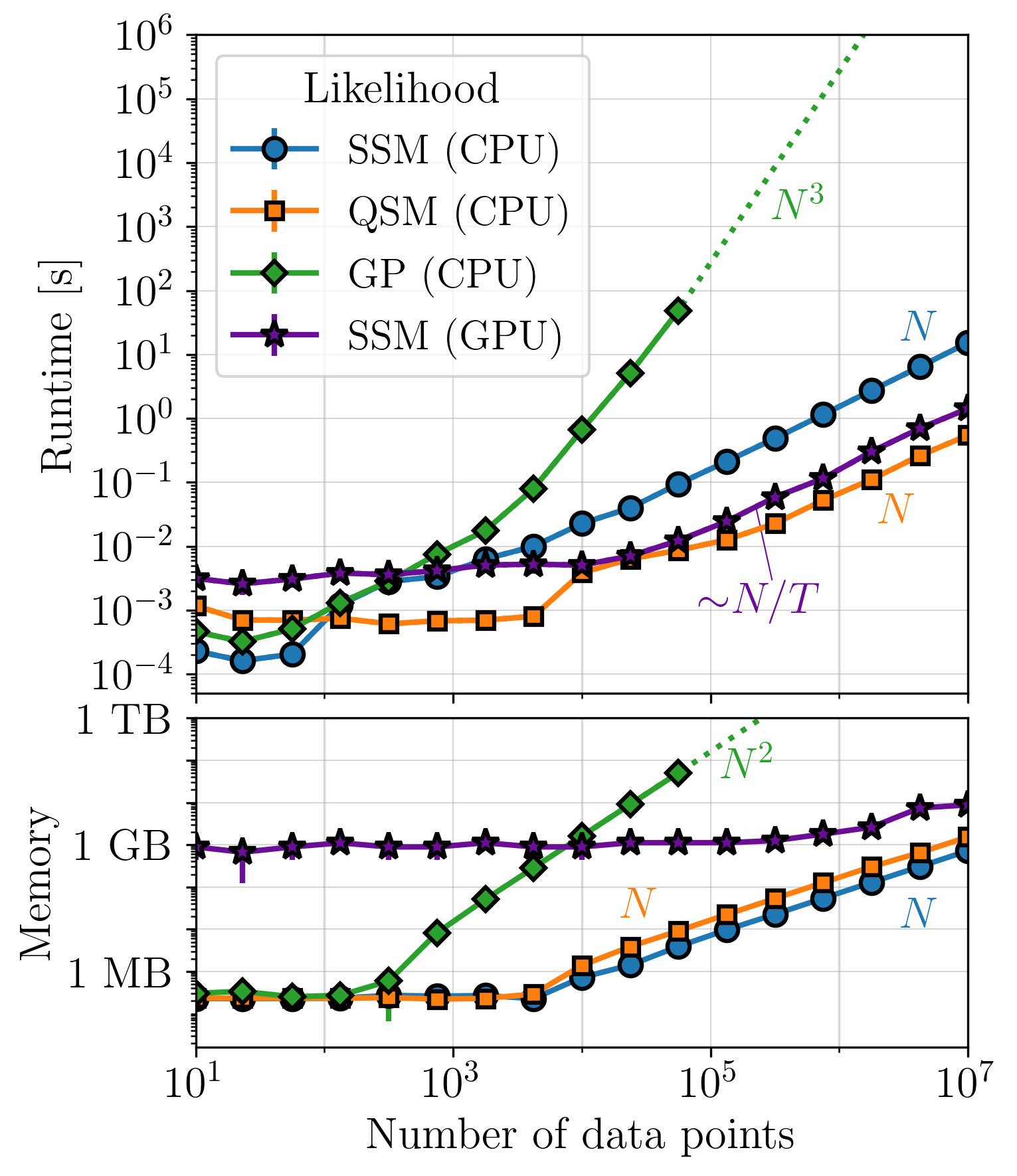
Integrated measurements#
When the measurements individually span finite time intervals with variable length and/or overlap with other measurements, we cannot take advantage of any quasiseparable optimizations in tinygp and so are forced to use the \(\mathcal{O}(N^3)\) solution there. This is the scenario in which smolgp has the most impactful advantage over previous methods.